The objective of this design process was the implementation of a unit written in SystemVerilog using a previously designed Multiply-Accumulate block. Taking the MAC, a 3x3 matrix and a vector were to be input into the system to perform Matrix Vector Multiplication. Eventually, the MVM will take in another vector for addition after the MVM in the second part of the project. Once the MVMA is implemented, the 3x3 matrix will be expanded to a 4x4 matrix along with the other vector lengths adjusted accordingly. In terms of control and data paths, a handshaking protocol is necessary to tell the system when its ready to take in inputs and when there are valid inputs to write in. This protocol is an important step and consideration in timing verification that will be observed later in the project. The eventual goal of the project will be to use this MVMA system as a neural network layer.
Adding memory elements to the multiply and accumulate blocks that were designed previously allowed for the implementation of a matrix vector multiplier with a three by three matrix input along with a vector of length three. A hand-shaking protocol is employed between the master and slave ports to ensure that valid data is being passed. There are two particular signals - "ready" and "valid", which are sent from the slave and master to the other respectively. When the master passes data to the slave, it also uses the "valid" signal to indicate that the data is indeed correct. The slave block sends back a "ready" signal to the master to show that it is prepared to take the passed data. With the synchronous nature of the system, triggered by positive clock edges, the only time when data should be passed is when both "valid" and "ready" are asserted. This protocol introduces complexity in terms of timing and in conjunction with reading and writing to memory.
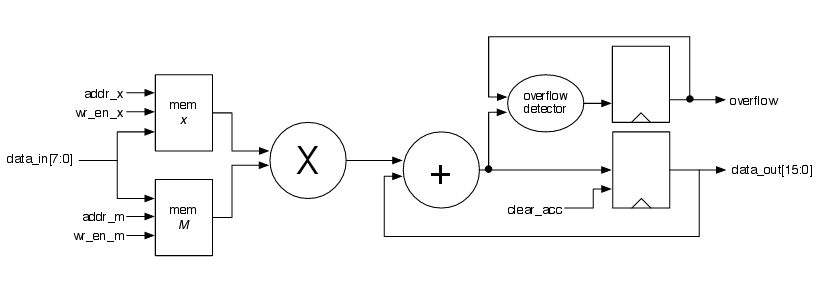
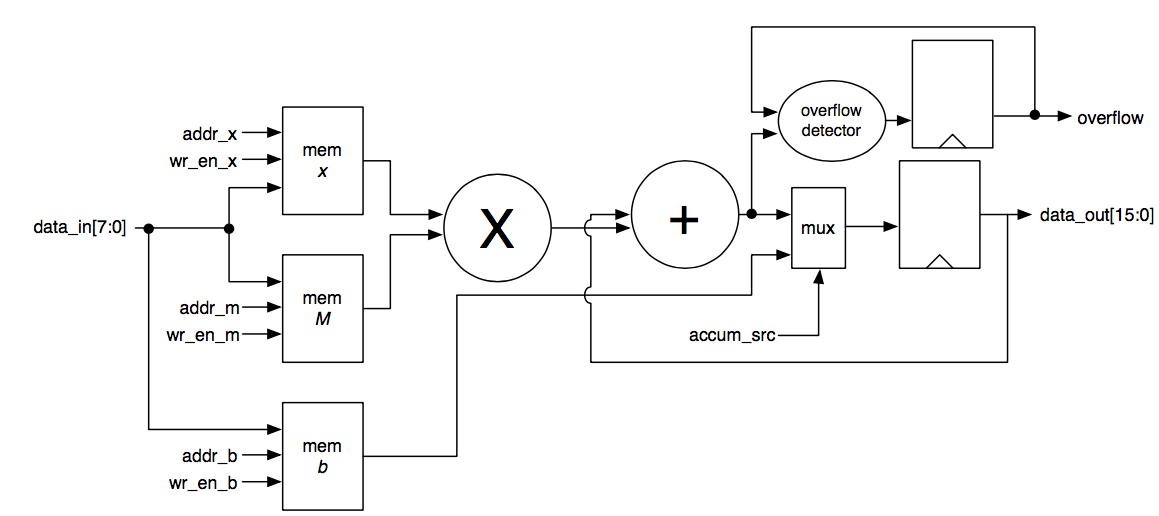
The inputs to the system will be sequentially sent, following the matrix row then vector order. These inputs will be multiplied then accumulated for each specific row, with an overflow detection when the output is larger than the sixteen bits assigned to it. When the accumulator is cleared for next matrix row-vector multiplication, the overflow will also be cleared to reset the detection for the next value. This part of the hardware design is the datapath, with the control signals to this separated and placed in a control module. Figure above shows the structure of the datapath to be implemented. Inputs other than the data are the control signals to each memory block.
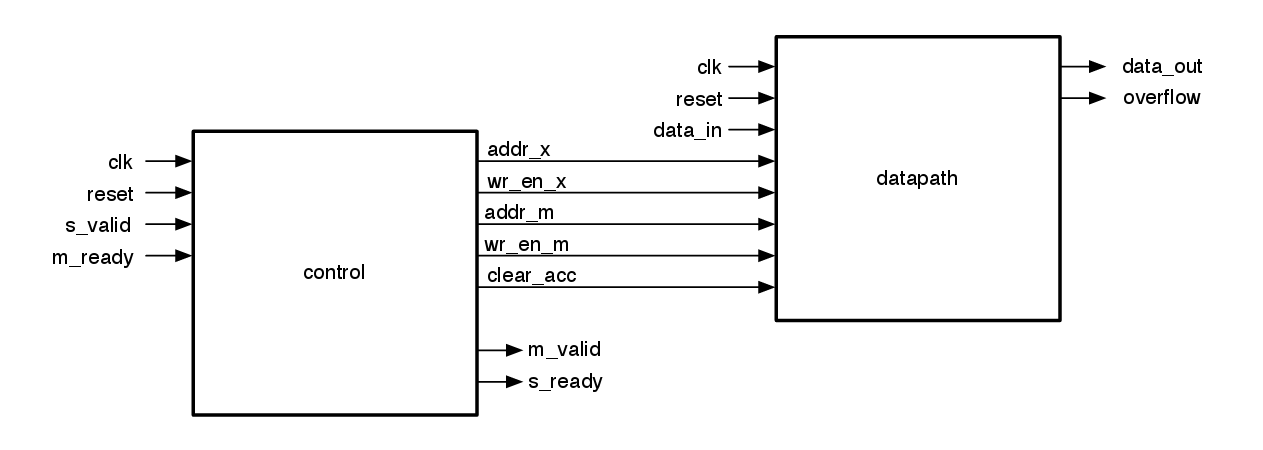
For ensured control over the system inputs controlling the datapath, the control module was written with interconnects to the datapath as seen in figure 2. The testbench used for verification was as important as the design process so that it could be known whether or not the design was working correctly or not.
Fig 2. Block diagram showing the control signals to be passed to the datapath [Figure Credits: Prof. Milder]
Given the 3x3 matrix with the 3 length vector, a natural question to ask is what the number of (specifically arithmetic) operations needed to multiply them is. There are 9 multiplications for each element of the matrix with the corresponding column value of the vector. There are then 6 additions total; 2 for each row of the resultant vector. This is total of 15 arithmetic operations. Generalizing the formula to account for a k x k matrix and k length column vector, one has k x k total multiplications, and k-1 additions per row of the output column vector. Since there are k columns, there are k*(k-1)=k^2-k additions total. The total arithmetic operation count would then be: k^2+k^2-k = 2k^2-k. It is noted that this is the mathematical answer, and is not the case for certain designs. When the accumulator is cleared (as in our design), a zero vector is added, thus bringing up the count to 2k^2
The control module in the program makes use of counters for the proper timing of assertion and deassertion of control signals. In addition to the general counter, there is also a separate counter for write cycles. For the first 0 to 11(9+3) counts, the input data is obtained and stored in the corresponding memory. From counts 12 to 19, the computation is performed and the data is outputted. In general, when the inputs are taken in, the count is increased until k-1 inputs are written in and immediately after the last k-th input is written in, the write_enable signals are set to 0 and the write counter is activated. A clock cycle later, the data is fed to the MAC. Depending on the counter values, the address signals and write enable signals are assigned. Whenever the write counter reaches value (n*k)-1 (where n goes from 1 to k), the enable signal is set high and at the next clock cycle the m_valid will be asserted. When the vector x address is 1 and the counter is greater than (k^2+k)-1 the accumulator will be cleared. Based on the counter values a specific code block will be called for executed.
Initially the rudimentary verification strategy was using the testbench provided to compare the circuit's simulated behavior with the timing requirements. After confirming proper operation, a random-number based testbench was created. A python script [tb_gen1.py] was written to generate the signals. The input signals "reset", s_valid, data_in, and m_ready are randomly generated and stored in the "part1_tb_inputdata.txt" file. The python script will also perform the matrix vector multiplication itself and generate the output signals s_valid, m_valid, data_out, overflow. Both input and output signals will be stored in the "part1_tb_outputdata.txt" file. This file was originally intended to be the simulation and to match all the signals, but due to slight complications this approach was abandoned and this file was used only in the case of a mismatch between the data files.
Initially the rudimentary verification strategy was using the testbench provided to compare the circuit's simulated behavior with the timing requirements. After confirming proper operation, a random-number based testbench was created. A python script [tb_gen1.py] was written to generate the signals. The input signals "reset", s_valid, data_in, and m_ready are randomly generated and stored in the "part1_tb_inputdata.txt" file. The python script will also perform the matrix vector multiplication itself and generate the output signals s_valid, m_valid, data_out, overflow. Both input and output signals will be stored in the "part1_tb_outputdata.txt" file. This file was originally intended to be the simulation and to match all the signals, but due to slight complications this approach was abandoned and this file was used only in the case of a mismatch between the data files.
To check the functionality of the circuit, the data_out and overflow signals were extracted and stored in a separate file ("part1_dataout.txt") for ease of comparison. The data_out and overflow signals will only be saved to the file when both m_valid and m_ready are high, similar to the functionality of the circuit. Since only the data_out, m_valid, and overflow signals of the DUT will be seen from an external viewpoint, it is safe to check only those signals. Even though the m_valid signal will be generated by the DUT, the data_out depends on the m_valid signals and there isn't any need to output this signal to the file and once again check the validity of the m_valid. Up to 1 billion clock cycles were run and compared for the circuit verification. Instructions on the script file usage are on the readme.md file.
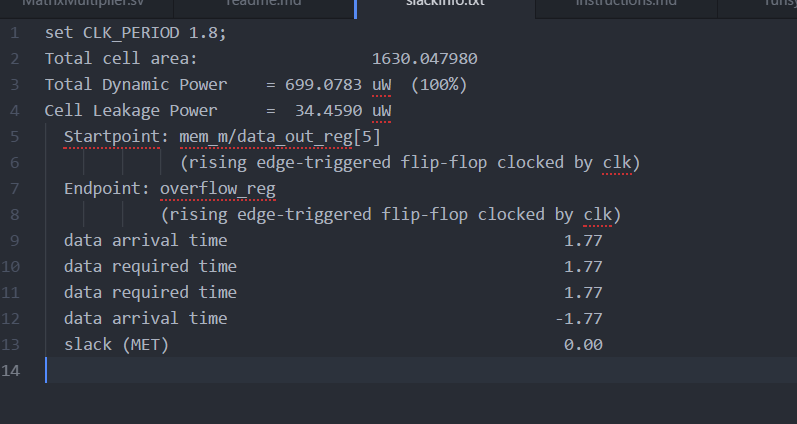
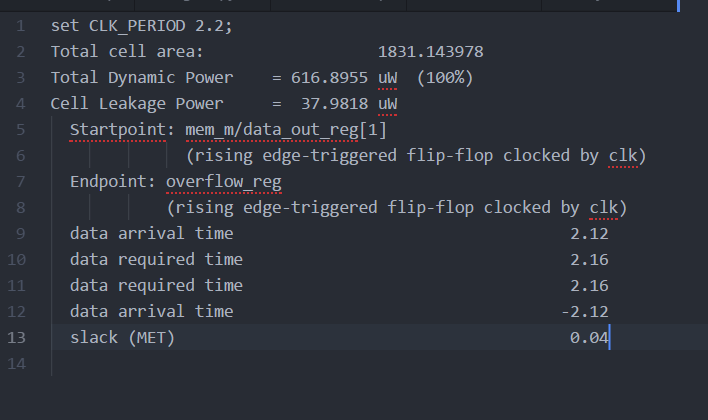
A script was written to extract the desired parameters of area, power, frequency, and the critical path location for the synthesized design. It is noted that the synthesis was run with the "ultra" configuration. These values are seen in Figure 3. The frequency can be obtained by taking the multiplicative inverse of the clock period, so 1/1.8ns=555MHz is the frequency. Total dynamic power is 699.08uW, cell leakage power is 34.46uW (Total Power=733.54uW),and total cell area is 1630.048um^2.
Fig 3. Part 1: Condensed Synthesis Report
Looking at the critical path, the start point is the beginning memory register, leading to the overflow register. This is much the same as the unpipelined MAC from the first project. Since there is no pipelining at this stage separating the combinational blocks, it stands to reason that the critical path would be one of the input registers to one of the output registers. In this case, with the synthesized blocks, the longest delay led to the overflow-detecting register.
Assuming that s_valid and m_ready are asserted input signals without any delay, the circuit will require 12 clock cycles to read the inputs, 3+1 clock cycles to compute and output one matrix vector multiplication result with k=3. When the DUT transitions from inputting the data to computing and outputting, one extra clock cycle is required to change the address as well as the write enable signals. Once the data set is obtained from memory, it is unnecessary to wait for the computation. As such, the next round of data inputs will be read from memory at the same time as computation occurs. This approach is the same for the last element, with the next set of inputs written in at the same time as the last computation. In this case, the design has a total clock cycle requirement of 12+1+3+3+3=22 cycles. This is the sum of the requirements from signal input to signal output. If the overlap were to be accounted for, the total number of cycles would be reduced by one, being only 21 cycles. The system delay is found to be 22 * 1.8ns = 39.6ns.
The area-delay product takes the given area of the design from the synthesis tool and multiplies it with the delay calculated for a complete computation. In the previous question, the later was found to be about 39.6ns while the total cell area is seen in figure 3 to be 1630.0479um^2. Multiplying these two values 39.6ns * 1630.0479um^2, the resulting value is 64.55us*um^2.
Total power consumed per ns is found in the synthesis report in Figure 3 to be 733.54uW. In the case that the system is computing a matrix-vector multiplication, the 39.6ns time for the completion of the sequence can be used with the power to calculate the energy required for said completion. Since P=E/T, E=733.54uW*39.6ns=29048.10fJ.
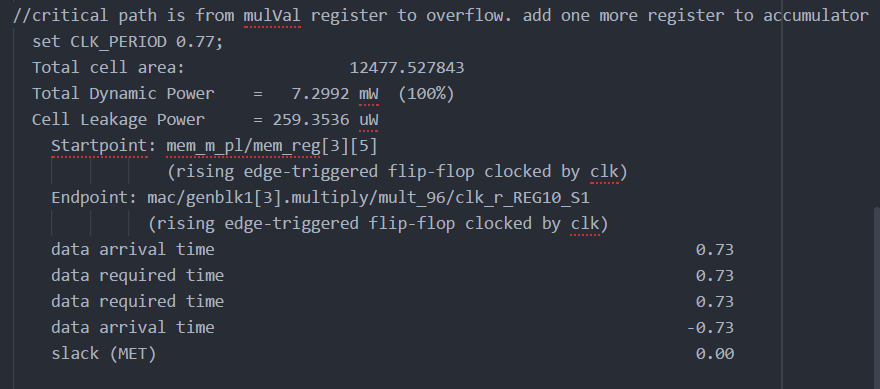
During the initial implementation of the MVM, it was discovered during synthesis that the a combinational loop was present in the design, producing a latch. The output of the MAC module was set as an input of the MAC module, creating this loop. This was not a desirable feature, so instead of feedback being handled combinationally, this problem was fixed by adding a temporary storage register in the MAC module called "mulVal". By storing the output int this module, and using the "dataout" signal as the feedback input, the loop was broken by the sequential block without affecting the desired logical operation.
Another problem was the method used for the control of accumulation (in avoiding multiple accumulations of the same input data) and output data computation. Using the change in the input signal (element from matrix m and vector x) as a control seemed to work at first, but when the testbench was run for a billion clock cycles, there was a moment where the matrix m and x did not change for 2 counter increments, thus proving that this way was not a robust way. This strategy was then abandoned and the whole code was rewritten with a delayed version of m_valid signal to prevent multiple accumulations.
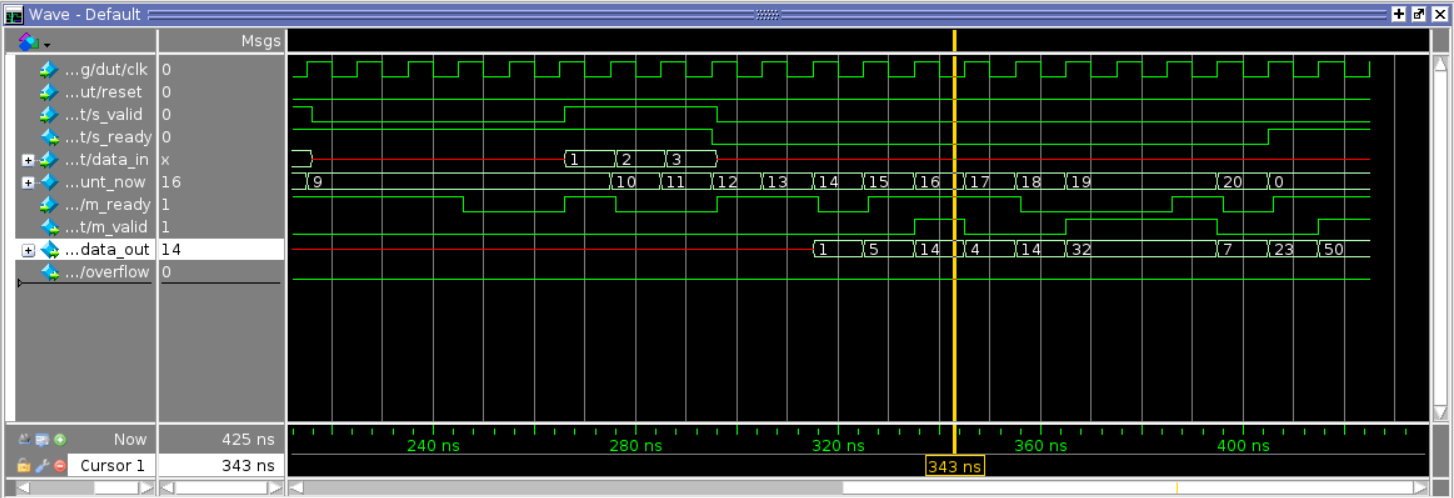
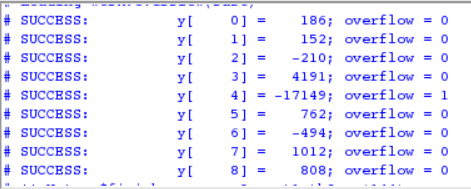
The simple testbenches were also successful, with the results of the first one in Figure 4 and shown as a waveform in Figure 5. The second provided testbench was also successfully completed as shown in Figure 6 and in waveform view in Figure 7.
Expanding upon the design of the 3x3 MVM computational system, the next part of the project was to implement a vector addition to the original MVM block. After the completion of the kxk (m matrix) MVM with k length vector x, a vector (b) of corresponding length k will be added. In this case, the order of input loading is the kxk inputs from m first, the k values from b next, then finally the k values from x. Since the addition of vector b is done after the MVM, but is loaded before the MVM is completed, extra memory is required. After storing b into memory, it can be set to feed back into the adder through the output register when a row of m*x is completed after 5 arithmetic operations. The sixth operation would be the final vector addition for that output vector row. Figure 8 is the high-level block diagram of how the design could be implemented.
Fig 8. Part 2: Provided block diagram of 3x3 MVM plus vector addition [Figure credits: Prof. Milder]
Fig 9. Part 2: Condensed Synthesis Report for MVM+VA
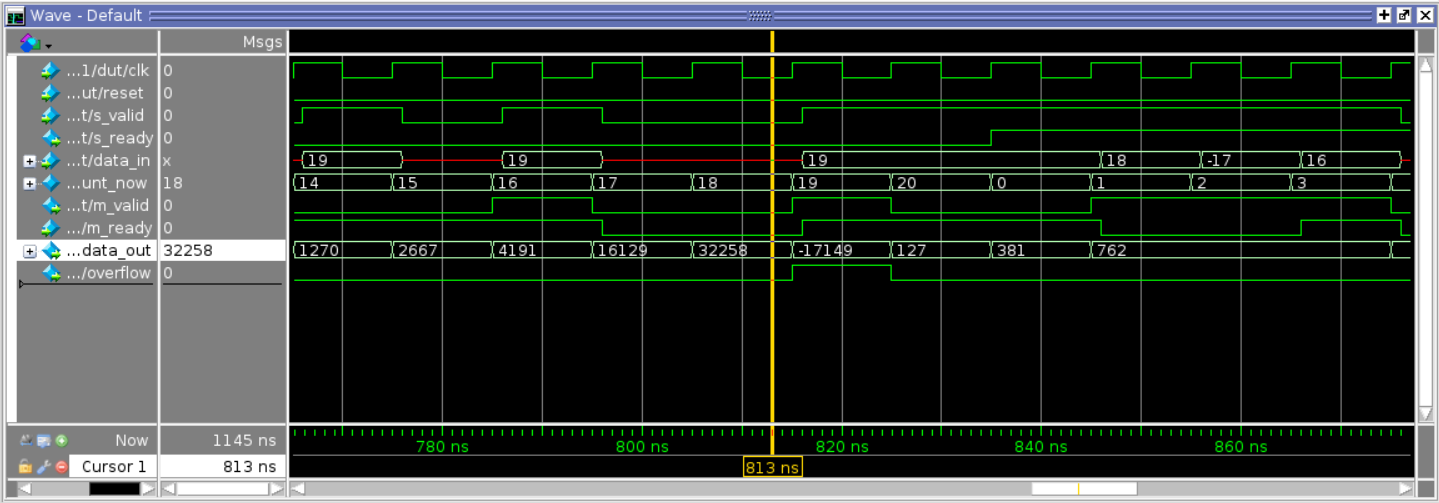
During verification, it was found that the addition of vector b did not behave the same when it was added to the front of the accumulation as opposed to the back. In the python script, the element of the vector b was added to the back. In the SystemVerilog code, it was added to the front. Assuming the range is from -10 to 10, if vector b was 10 while the matrix m and vector x accumulation step was (12 + -4), adding 10 (b) to the front will yield (10+12 = -8 + -4 = -12) and adding to the back will yield (8 + 10 = 18). Depending on the situation the overflow can be high or low, and this error resulted in disparity between the python script and the SystemVerilog results. The python script was then adjusted to add vector b to the front in order to fix this error. The number of runs was increased until one billion clock cycles to verify the correct functionality of the circuit. Figure 10 is the waveform view of a single complete cycle and the behaviors of the input signals as well as the control signals.
Fig 10. Part 2: Waveform View of One Complete Cycle
The operational range of the MVM+VA system was increased from k=3 to k=4. This meant that the number of arithmetic operations changed to 32 from 18 mathematically (21 to 36). The sizes of the matrix m and vectors x and b were thus both increased as well, with matrix m being a 4x4 matrix with 16 elements and the two vectors being of length 4.
The source code was parametrized from the beginning, due to experiences had during project 1. The code includes parameters such as matrixWidth, mSize, vSize, vectorWidth and countWidth to aid in modification to the code without the need to manually change each one at every location. The parameter values of the matrix and vectors are assigned depending on their sizes. "matrixWidth" is the number of bits required to store the matrix, so if it's a 4x4 matrix, then matrixWidth is 4 (4 bits for 16 elements).
To generalize, a kxk matrix requires log_2(k*k) for its width. "mSize" is the matrix size (k*k). "vSize" is the vector size (k*1). "vectorWidth" is number of bits required to store the vector, which would be log_2(k). "countWidth" is the number bits required to store the counter.
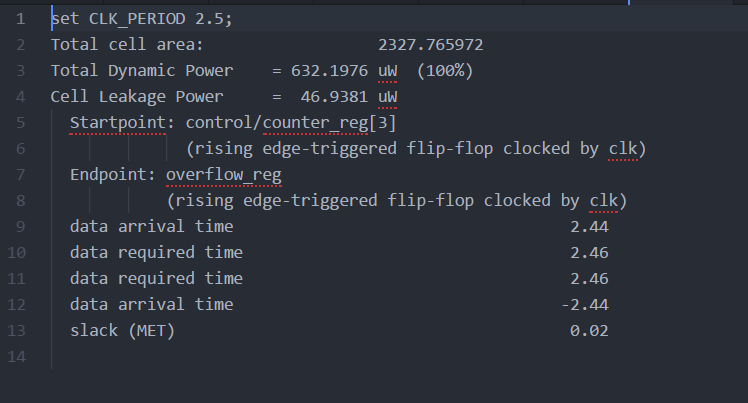
For a kxk MVMA calculation, the counter range is from 0 to 2*(k*k+k)-1, which is log_2(range) rounded up. Having parametrized the code, changing the code is simple, as mentioned earlier. As k increases, the control block will change as well to accommodate for the increase in matrix size and vector length. More specifically, the "if statements" monitoring the counter will be changed by the parameters as to meet the timing changes. Since the control block will send the signals to all the other blocks, there won't be any manual changes to the timing needed. Other than given memory, power and area limits imposed by the tool, there is no practical limit on the value of k.
Fig 11. Part 3: Condensed Synthesis Report for 4x4 MVMA
The design so far was built for functionality, with the focus being on achieving the proper timing of input signals and computations so the output would be correct. Some base optimizations were done in the previous module to streamline the process without modifying the datapath too much. A delay-optimized focus of the system would include multiple different design methodologies that would serve to greatly decrease delay. The limitation imposed on this part was the immutability of the input/output ports. Three different techniques were used to boost operational speed; pipelining, additional parallelism, and DesignWare Component selection.
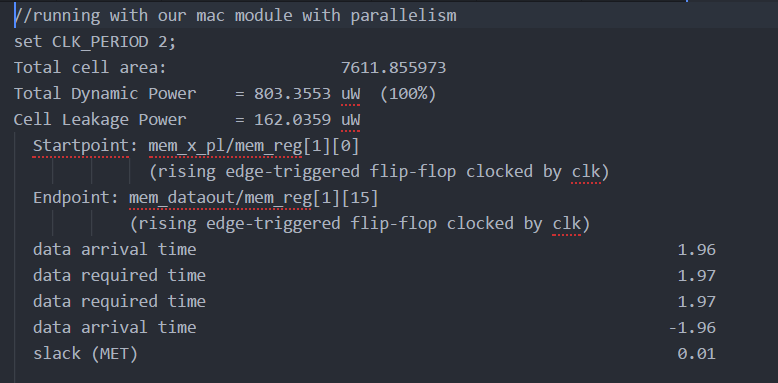
In the previous project, pipelining was explored for faster operation of a MAC module. Registers were added between combinational blocks to shorten critical path drastically. This was implemented here was well. Additional parallelism was implemented by modifying the memory module to have serial input and parallel output. In addition to input memory, a memory module was added to the output with parallel in and serial out feature. By obtaining the data from memory in parallel, the time required to change addresses is eliminated. The counter has to wait one clock cycle to perform computation and output the data to outputMemory but can be overlapped with obtaining the next input data. Thus, while the counter needs to increment to 24 counts to obtain the input data, computation and outputting will be performed during the next cycle simultaneously. Parallelism helped in reducing the clock period from 2.5ns to 2ns, increasing the frequency from 400MHz to 500MHz. Figure 12 shows the met clock period with parallelism.
Fig 12. Part 4: synthesis report after parallelism
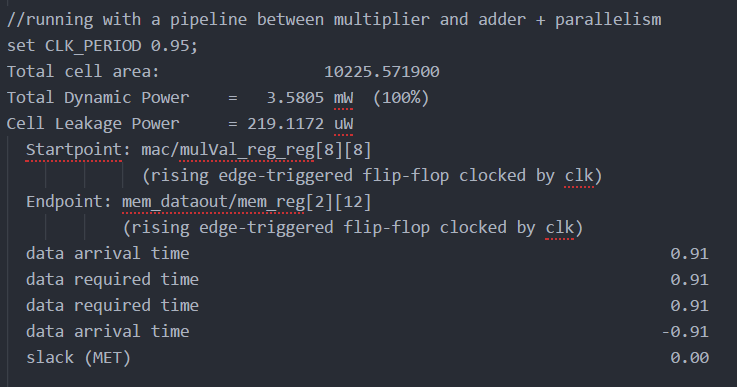
As done in the first project, pipelining was implemented by adding a register between the multiplier and accumulator combinational blocks. As seen in the synthesis report, Figure 13, the critical path is from the input memory register to the output memory register. Adding the pipelined register in the combinational logic will reduce the clk period by shortening the critical path. This effectively doubled the clock frequency from 500MHz to 1.05GHz (or halved its period from 2ns to 0.95ns).
Fig 13. Part 4: synthesis report after pipelining
The method of modifying control logic was one of the baseline optimizations done since the first part. Input and output data is overlapped, helping to reduce the wait time in outputting the last element. In this part, since there is output memory, the input and output data will be completely overlapped unless m_ready is 0 for a long time.
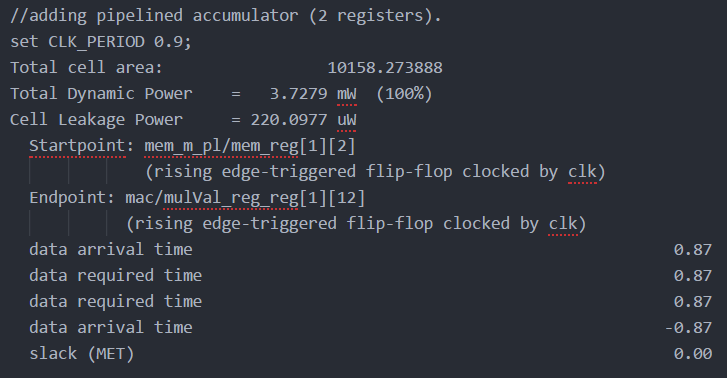
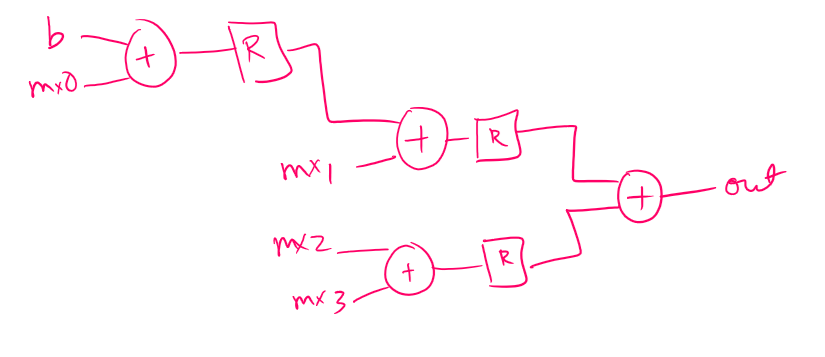
After adding the pipeline, the critical path is from multiplier to the output. The accumulator was completely dominated by combinational logic. Registers were added to pipeline the accumulator. This reduced the clock period further by another .05ns to 0.90ns, as seen in Figure 14 from 0.95ns. Total cell area was actually decreased a small amount for this run, but power was increased as expected with the increased frequency.
Fig 14. Part 4: synthesis report after addition of registers to the accumulator
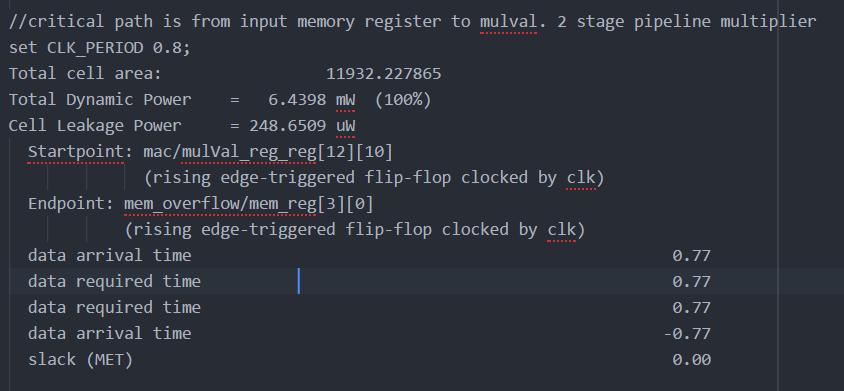
With critical path set back again at the input memory register to the multiplier register, the DesignWare component method was used to increase clock speed further. The design was implemented using multistage multipliers provided by DesignWare. The first 2 stages were implemented, and the synthesis report is shown in Figure ref{fig:mesh15}. The clock period was reduced by another 10ns to 0.8ns. The beginning of the critical path was once again shifted to the multiplier register and the end of the path to the overflow memory register. This is due to the fact that the accumulator originally used only 2 registers.
Fig 15. Part 4: synthesis report after addition of 2 stage multiplier
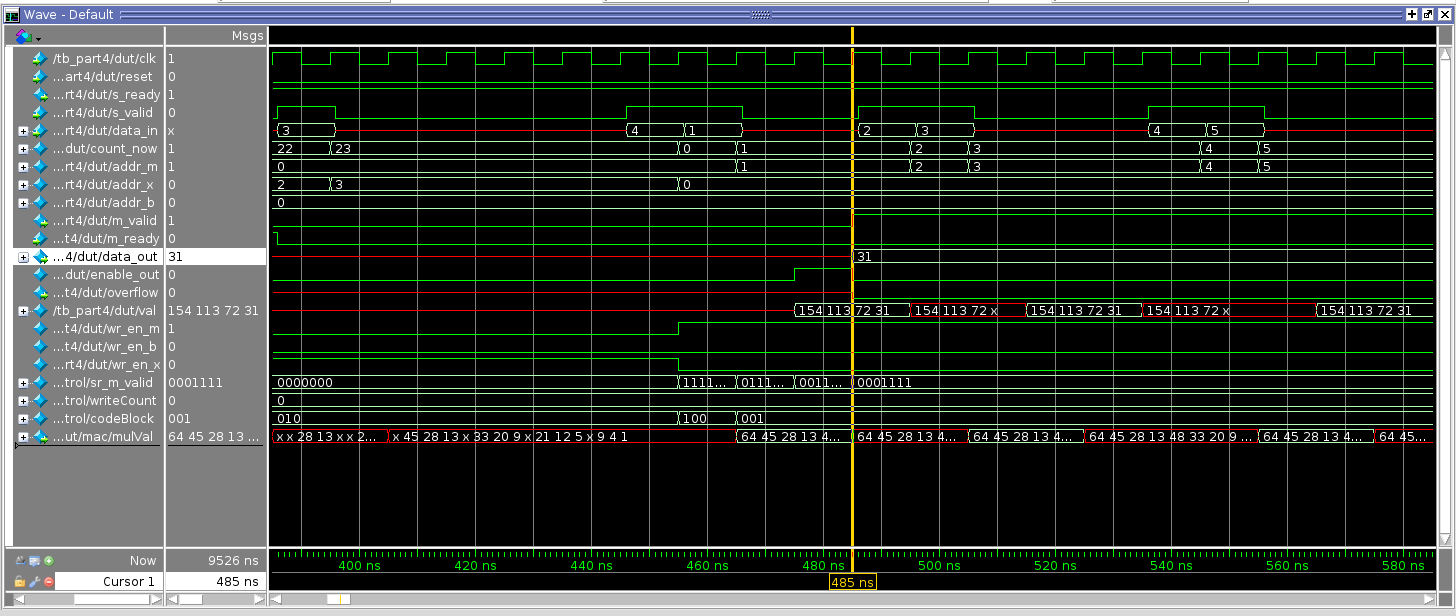
Adding a register at b and at mx0 reduced the clock period to 0.77ns (Figure 17 - offset was increased to 4). There were no more ideas for the simplification of the accumulator at this point. The critical path start was shifted to input memory with the end being the 2-stage multiplier. The waveform is included to show the offset of 3. After the counter changes to 0 on the 3rd clock cycle, the data is outputted (figure 16).
Fig 16. Part 4: Waveform of Pipelined Multiplier and Pipelined Accumulator
Fig 17. Part 4: Synthesis report- Addition of another register to the accumulator
Fig 18. Part 4: Accumulator setup
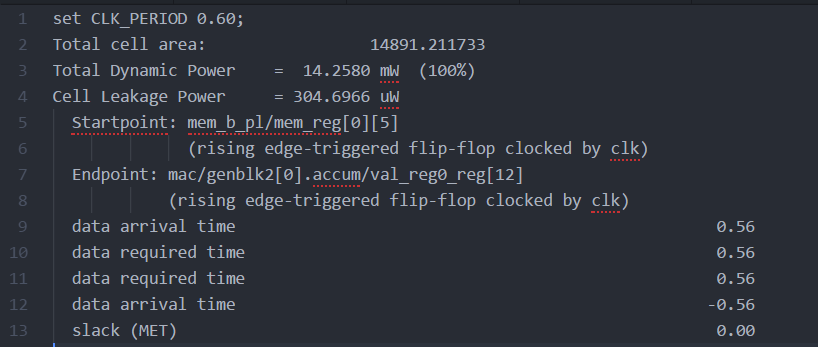
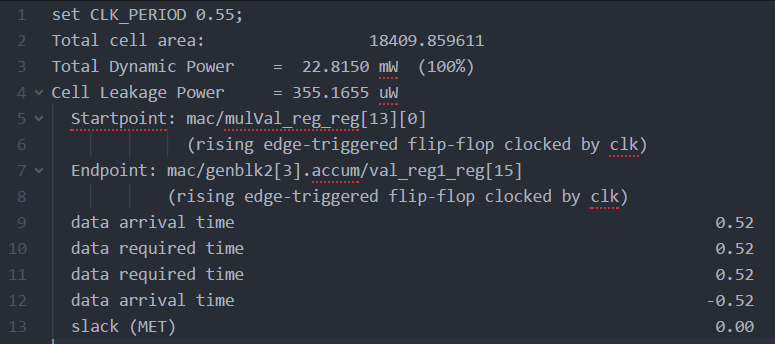
More multiplier stages were added like in the first project. First, a 3-stage pipeline was tested. This reduced the clock period down to 0.6ns(Figure 19). The critical path start changed to the input memory register b and the end to accumulator. The stages of the pipeline were increased to 4, then 5 then 6. Each stage was tested and the clock period was still at 0.6ns (Figure 20) for the 4-stage. For the 5-stage and 6-stage pipeline, the clk period decreased, but remained at 0.55ns(Figures 21 and 22 respectively)
Fig 19. Part 4: Synthesis Report- 3 stages
Fig 20. Part 4: Synthesis Report- 4 stages
Fig 21. Part 4: Synthesis Report- 5 stages
Fig 22. Part 4: Synthesis Report- 6 stages
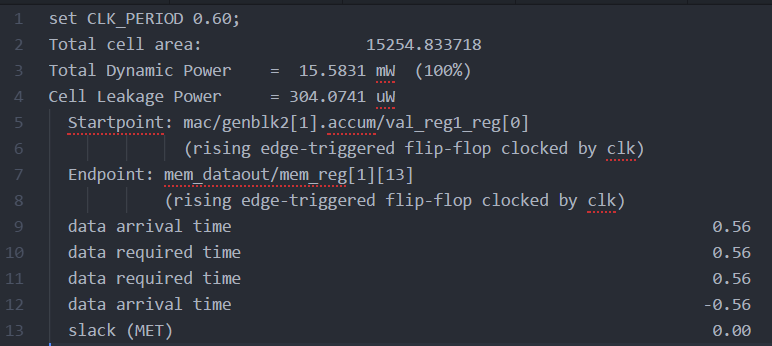
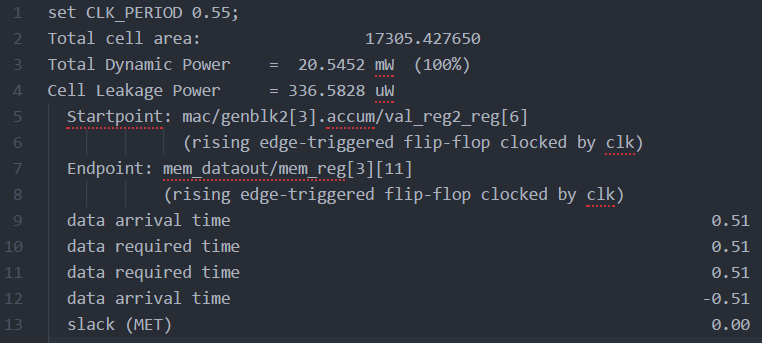
The 5-stage design was used since it had the fastest clock speed of 1.81GHz. Figure 21 gives the total cell area of 17305.427um^2, Total Dynamic Power of 20.5452mW, cell leakage power of .336mW (Total Power=TDP+CLP= 20.881mW), and the critical path beginning at the accumulator to the dataout memory register.
After completing all the parts, it was found that we incorrectly assumed the input order to be m-x-b. Because the input order is m-b-x, the SystemVerilog and testbench code for parts 2 and 3 had to be slightly altered to fix the order. Part 4 required a complete rewrite since we implemented an optimization for vector b inputs that would perform computation as the vector b elements come in and eliminate the necessity of a memory module.
The code was tested for 1 million clock cycles to confirm the functionality of the circuit. The part4 testbench code was altered to include offset functionality. Every time a new feature was added, the corresponding offset parameter was set in the verilog code and tested with the testbench file. To test if our circuit will stall in the case that m_ready never arrived, we used an additional manually created testbench input file called part4_tb_manual_inputdata.txt. The output was manually checked for confirmation.
Designing a Parity Generator using xor gates in the static cmos 45nm technology. The design objective is to obtain the best power delay product. The parity generator drives an external load of 12fF. The propagation delay of the circuit has to be less than 200ps.
VLSI Netlist Partitioning using Fiduccia Mattheyses
Fiduccia-Mattheyses(FM) is an algorithm which handles the problem of dividing a large netlist, with many nodes, into two sets under particular size constraints. Partitioning is a key part of Very Large-Scale Integration (VLSI) design. VLSI design can typically be broken into the main stages of partitioning, floorplanning, placement, and routing. In Partitioning, the goal is minimizing the cutset size, which is defined as the number of edges connecting two partitions. Of the many approaches taken to solve this problem, the most common is the Kernighan-Lin(KL) approach. This approach involves swapping pairs of nodes to decrease the cutset size. However, this algorithm is limited to only balanced partitions, and does not include the concept of a hyper edge. Fiduccia-Mattheyses is a modification of the KL approach to include the concept of hyperedges, and adds a bucket list data structure to decrease the time complexity of the algorithm from O(n^3) to O(n^2). --A group project done along with Ryan and Nick
Constructed, optimized, and evaluated targeted Automatic Test Pattern Generation(ATPG) tool using the PODEM algorithm for fault detection. The PODEM algorithm is implmented using functions like backtrace, getObjective, checkFault, and simulateFullCircuit. In addition, the updateDfrontier function will be used to recursively run through the benchmark circuits from primary outputs to primary inputs looking for D or Dbar. utilizing gates in the Dfrontier the ATPG will generate the testvectors. In order to increase the speed of the algorithm, event driven simulation was implemented for 10x speed increase. The test vector size were reduced by running fault simulator and utilizing don’t cares in the test vector to obtain only unique faults. SCOAP metrics were calculated for each inputs and output of the gates and were used to make smarter decision while running algorithm. More details to be added.
Gerbmerge is software written in python that will combine multiple gerber files into one super board. Gerbmerge offers both manual and automatic (optimization algorithms) as means of board placement. Because eagle cad design software has a limitation of 100x80mm routing area (express) or 160x100mm routing area(edu) , multiple boards cannot be combined together without requiring to upgrade a paid version. To work around this limitation, we can combine the gerber files generated from the eagle instead. By combining the gerber files, we also avoid the problems caused by the panelizing script which redefines all the components to different names. (We combined boards of 10 people and checking each person's board for name conflict is an annoying and time consuming task). The gerbmerge code is originally written by ruggecircuits, here I added some extra programs and altered the code to enable ease up merging the PCBs. This tutorial is a detailed explanation of how to accomplish this goal.
Improved Ammeter PCB design from scratch + 3D printing
This current meter design is intended to minimize the effects of burden voltage that is present in most Multimeters in the market. The current meter is designed to read up to 7A. The maximum current rating is set to be 8A (the fuse will break at this point) and will only be able to read positive DC currents. The circuit can be powered by a battery with a voltage ranging from 2.5 to 5v, in this design 2-AAA battery is used as a power source i.e 3V source. The Analog current measurement will be sampled at 12kSPS (based on atxmega32 specs), and the digital output will have 12-bit resolution.
The current is read by measuring the voltage that flows across a shunt resistor. The shunt resistor is specially chosen to have current sense technology, where the resistors packs have 4 terminals, 2 for current flow, and 2 for current measurement. The voltage across the resistor is read using the Atxmega micro controller’s built in Analog to digital converter(ADC).
A LCD touch screen is added to display the current readings such as peak, instantaneous, rms etc. In addition the LCD will be used to graph continuous data assuming I will finish the programming on time. Since the programming had to go through a number of revisions, a PDI communication will be implemented to modify the code as intended. In addition to serving as a normal current meter, A USB port will be added to monitor the current usage of mobile phone or other devices charged using USB. A micro usb port will be used as the input and USB as output.
The course planner is designed using list/array data structure where students can record the courses they want to take in order of preference. A course contains general information such as course name, course code, course section, instructor, etc. The planner should be able to record a total of 50 courses. The program provides the ability to add courses, remove courses, get courses, print the planner, Filter courses, search courses, backup planner and obtain the size of the planner.
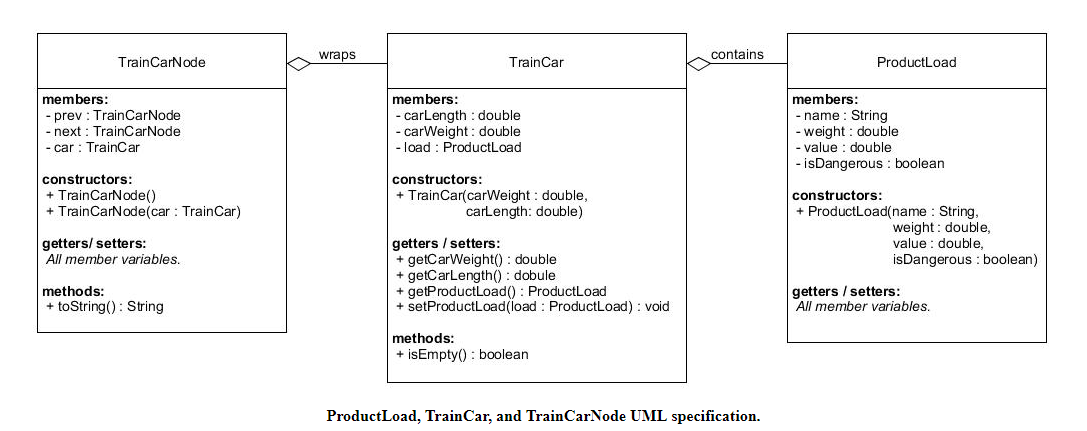
Designed train car manager for a commercial train, modelled using a Double-Linked List data structure. Train car manager consists of a chain of train cars, each of which contains a product load. A product load has a weight, a value, and can be dangerous or safe. The train car manager will be able to add and remove cars from the train, set the product load for each car, and determine useful properties of the train, such as it's length, weight, total value, and whether it contains any dangerous product loads. All the properties completes in O(1) time complexity.
Most programming languages are organized as structured blocks of statements, with some blocks nested within others. Functions, which are examples of such blocks, execute statements and other blocks contained within the them. Similarly, flow control strucutres, such as for and while loops, are blocks which can be executed several times subject to some condition. The Python programming language is an example of a language which follows this principle, and is even flexible enough to allow functions to be nested within functions!.
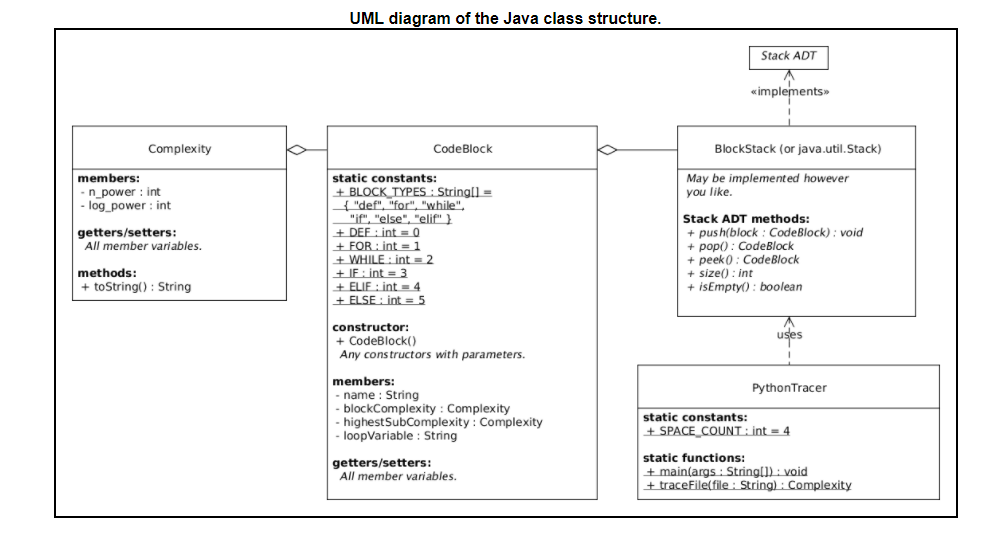
A code tracer program is designed which takes the name of a Python file containing a single function and outputs the Big-Oh order of complexity of that function. BlockStack class is implemented to determine the complexity of blocks with nested blocks, and use the rules of Big-Oh complexity to determine the total complexity for the function.
Imitating a simple network of routers by writing a simulator using Queues. In the field of networking, information is packed into a single entity called a packet. A packet contains the sender's information, and also extra overhead bits that describes certain properties of the packet. Some of these bits are used to determine the path it takes to maneuver through the network. Packets travel through routers across the network, until they have arrived to their specified destination.
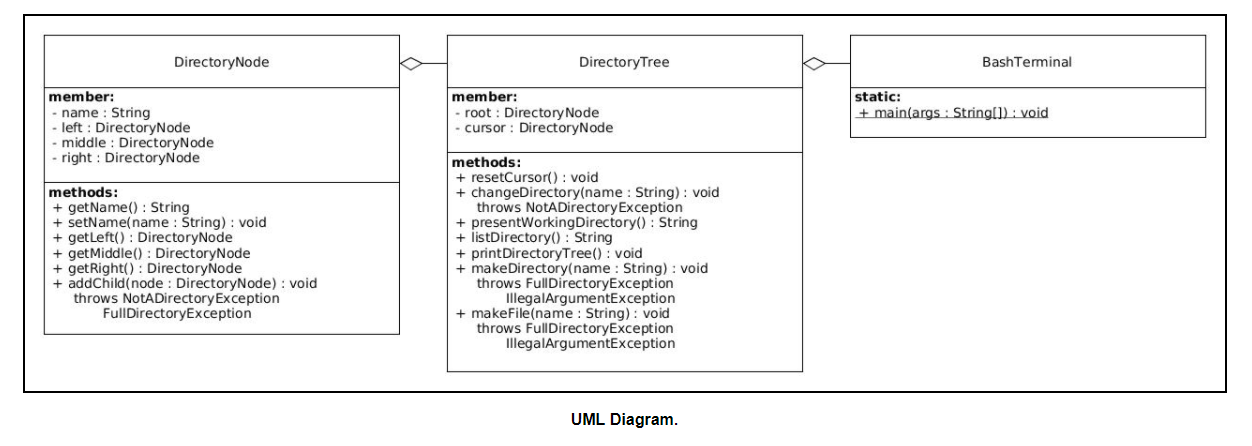
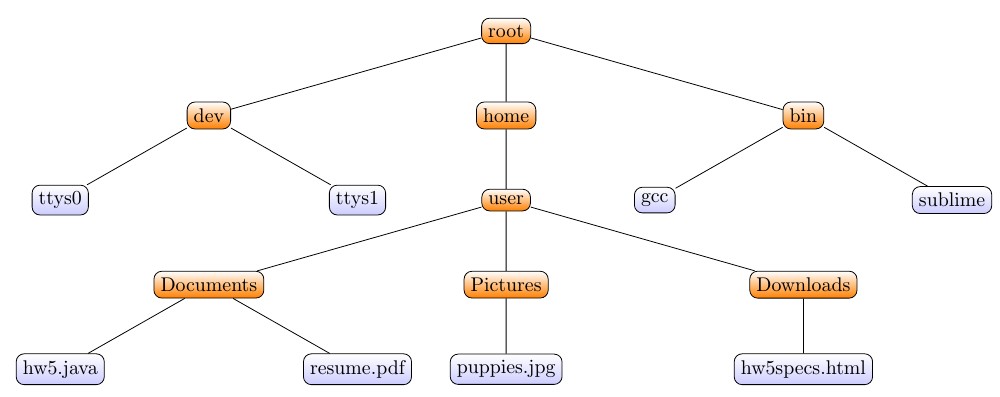
Modeling a file system using a ternary (3-child) tree data structure. In most operating systems, files are stored in directories. These directories may contain other directories along with files. In addition to a file system, an OS typically also provides a shell, which is an interface allowing you to run programs and move through the file system.
Designing the Auction site data base using Hash Table Data structure. A very basic array can store information without a problem, but is inefficient when we are constantly storing and searching for data. The table is created to increase the efficiency and avoid such problems. Tables store data using a tuple . Ideally, this will reduce the algorithm to O(1). For this project, real auction data from ebay is utilized. The data will be in the form of an XML file. The program will read this xml file and build a hash table based on the data.
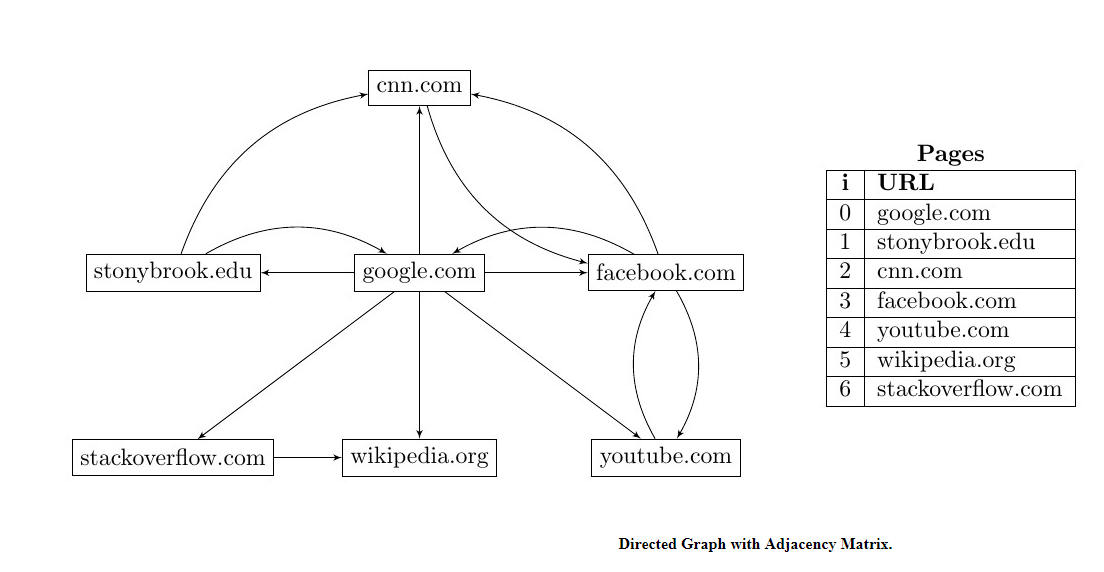
Implemented a directed graph of WebPage objects by reading pages.txt and links.txt. Once the graph is constructed, the program will run a basic search engine that prompts the user to enter a keyword. The program will then perform the PageRank algorithm, and display the pages to the user in tabular form sorted by descending PageRank.
Smart outlet controlled by sunrise/sunset/app [IoT]
I wanted to have a night lamp that will turn on after sunset and turn off in the middle of the night/ sunrise. The timers available at Home Depot or other hardware stores only allows to set a time. Since in USA there is daylight saving time, it had to be changed. To solve this, the outlet is connected to the internet to obtain the sunset timings daily. This project used Spark core to control the power outlet and IFTTT API to obtain the timings of sunset/sunrise/weather. As shown in the video at the above link, the Outlet was turned into a IoT device. This project was a featured project on instructables website on Jan 11, 2016.